おすすめのプロンプト
frieren from sousou no frieren,impasto style,beautiful color, detailed, aesthetic
best quality,masterpiece,vivid color,1girl,solo,bangs
おすすめのネガティブプロンプト
worst quality:1.3,low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxl_neg
| サンプラー | Euler Ancester | |
| ステップ数 | 28 | |
| cfg | 7 to 9 | |
| CLIP スキップ | 1 | |
| vae | sdxl-vae | |
| 解像度 | 832×1216, 1216×832, 1024×1024 | |
おすすめのハイレゾ(高解像度)パラメーター
| 高解像度ノイズ除去強度 | 0.37 | |
ヒント
モデルバージョンの主な特徴
新增了143个触发词。该版本是 AIDXLv0.5 的测试版本,新风格并不稳定。如果不是为了尝鲜,我更推荐 AIDXLv0.41。
Add 143 new trigger words. This version is a beta version of AIDXLv0.5. The new styles are not stable. I would recommend AIDXLv0.41 for better experience.
モデル開発者スポンサー
モデル紹介(英文部分)
I 目次
この紹介では、以下のことを学びます:
-
モデル情報(セクション II 参照);
-
使用方法の指示(セクション III 参照);
-
トレーニングパラメーター(セクション IV 参照);
-
トリガーワード一覧(付録 部分 A 参照)
II AIDXL
アニメ イラスト ディフュージョン XL、またはAIDXLは、スタイリッシュなアニメイラストを生成するモデルです。 特定のトリガーワードで800以上(更新ごとに増加中)のイラストスタイルを引き出すことができます(付録 A 参照)。
利点:
-
伝統的なAIのポージングではなく、柔軟な構図。
-
乱雑よりも技巧的なディテール。
-
アニメキャラクターをより理解しています。
III 使用ガイド
1 基本使用法
1.1 プロンプト
-
トリガーワード:画像をスタイリングするために付録 A のトリガーワードを追加します。 適切なトリガーワードは大幅に画質を向上させます;
アーティストスタイルのトリガーワードの重みを減らします。例: (by xxx:0.6)。
-
セマンティック整理:プロンプトのタグや文を並べ替えることで、モデルが意味を理解するのを助けます。
推奨されるタグの順序:トリガーワード (by xxx) -> キャラクター(フリーレンシリーズからフリーレンと名付けられた女の子) -> 種族(エルフ) -> 構図(カウボーイショット) -> スタイル(厚塗りスタイル) -> テーマ(ファンタジーテーマ) -> 主な環境(森の中、昼) -> 背景(グラデーション背景) -> アクション(地面に座る) -> 表情(表情なし) -> 主な特徴(白髪) -> 身体特徴(ツインテール、緑の目、開いた唇) -> 衣服(白のドレスを着た) -> 衣装アクセサリー(フリル) -> 他のアイテム(猫) -> 二次的な環境(草、サンシャイン) -> 美的特徴 (美しい色, 詳細な, 美的) -> 品質 ((best quality:1.3))
-
ネガティブプロンプト:(worst quality:1.3)、low quality、lowres、messy、抽象的、醜い、異形の、悪い解剖学、ドラフト、変形した手、融合した指、署名、テキスト、多重ビュー
1.2 生成パラメーター
-
解像度:棒 ピクセル数(=幅 * 高さ) が1024*1024 に近く、幅と高さが32で割り切れる場合、AIDXL は最適な結果を出します。例:832×1216 (2:3)、1216×832 (3:2)、および 1024×1024 (1:1) など。
-
サンプラーとステップ:「Euler Ancester」サンプラーを使用し、WebUIで「Euler A」と呼ばれます。 7〜9 CFG スケールで約28ステップでサンプルします。
-
『精錬』:text2image から生成された画像は時折ぼやけるため、その場合は image2image あるいはインペインティングなどを使用して『精錬』する必要があります。
シンプルに拡大する場合は以下を参照してください: Upscale to huge sizes and add detail with SD Upscale, it’s easy! : r/StableDiffusion (reddit.com)
-
他のコンポーネント: 追加の精錬モデルは不要です。モデル自身のVAEまたは
sdxl-vaeを使用してください。
Q:モデルカバーを再現するにはどうしたらいいですか?同じ生成パラメーターを使ってもカバーと同じ画像が再現できないのはどうしてですか?
A:カバーに示された生成パラメーターはNOTテキスト to 画像のパラメーターですが、拡大用の画像 to 画像 パラメーターです。ベース画像は主に Euler Ancester サンプラーによって生成され、DPM サンプラーではありません。
2 特別用途
2.1 一般化されたスタイル
バージョン 0.7 から、AIDXL は似たスタイルをいくつかまとめ、一般化されたスタイルのトリガーワードを導入しました。これらのトリガーワードはそれぞれが 一般的なアニメーション イラスト スタイル カテゴリを表しています。一般スタイルのトリガーワードは、その単語の意味が示す芸術的な意味に必ずしも準拠しませんが、特別に再定義されたトリガーワードであることに注意してください。
2.2 キャラクター
バージョン 0.7 から、AIDXL はキャラクターのトレーニングを強化しています。いくつかのキャラクター トリガーワードは Lora の効果を既に達成しており、キャラクターの概念を独自の服装からうまく分離することができます。
キャラクターのトリガー方法は: {キャラクター} \({著作権}\)。 例として、アニメ「サイバーパンク: エッジャーナーズ」のヒロイン ルーシー をトリガーするには lucy \(cyberpunk\) を使用します。ゲーム「原神」のキャラクター 甘雨 をトリガーするには ganyu \(genshin impact\) を使用します。 ここで、「lucy」と「ganyu」はキャラクター名であり、「\(cyberpunk\)」と「\(genshin impact\)」は対応するキャラクターの出典であり、括弧はスラッシュ「\」でエスケープされて、 重み付きタグと解釈されるのを防ぎます。 一部のキャラクターにとって、著作権部分は必須ではありません。
バージョン v0.8 から、さらに 簡単な トリガー方法があります: a {girl/boy} named {キャラクター} from {著作権} series。
キャラクタートリガーワードの一覧については: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co)。さらに、このドキュメントでは言及されていない追加のトリガーワードも含まれている場合があります。
一部のキャラクターには、追加のトリガーステップが必要です。使用時に、単一のキャラクタートリガーワードで完全にそのキャラクターを再現できない場合は、プロンプトにキャラクターの主な特徴を追加する必要があります。
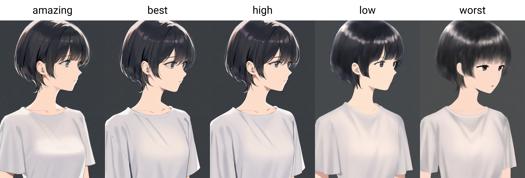
AIDXL はキャラクターの着せ替えをサポートしています。キャラクタートリガーワードには通常、キャラクター自体の服装の特徴が含まれていません。キャラクターの服装を追加したい場合は、プロンプトに服装タグを追加する必要があります。例として、銀のイブニングガウン、深いネックライン はゲーム 碧蓝航線 からamazing quality, best quality, high quality, normal quality, low qualityおよびworst quality。
品質タグに追加の重みを加えることをお勧めします。例:(amazing quality:1.5)。
2.4 美的タグ
バージョン 0.7 以降、美的タグが導入され、画像の特別な美的特徴を記述しています。
2.5 スタイルのマージ
いくつかのスタイルをカスタマイズしたスタイルにマージすることができます。「マージ」とは実際には同時に複数のスタイル トリガーワードを使用することを意味します。例として、春麗、驚異的な品質、(by よねやま まい:0.9), (by chi4:0.8), by ask, by modare, (by いっきしてい:0.9).
いくつかのヒント:
-
スタイルの重みと順序を調整して最終的なスタイルを調整します。
-
プロンプトに追加するのではなく、前置します。
IV トレーニング戦略とパラメーター
AIDXLv0.1
SDXL1.0をベースモデルとして使用し、約22kのラベル付き画像を用いてコサインスケジューラーで100エポック程度トレーニングしました。その後、学習率2e-7と同じ他のパラメーターを使用してBモデルを取得。それにより、モデルAとBを統合したAIDXLv0.1モデルを取得しました。
AIDXLv0.51
トレーニング戦略
AIDXLv0.5からのトレーニングを継続し、トレーニングを2つのランでパイプラインして実行:
-
ロングキャプショントレーニング:データセット全体を使用し、いくつかの画像を手動でキャプションしています。U-Netとテキストエンコーダーを共にAdamW8bitオプティマイザーでトレーニングし、高い学習率(約1.5e-6)をコサインスケジューラーで採用し、学習率が閾値(約5e-7)未満になると停止。
-
ショートキャプショントレーニング:ステップ1の出力からトレーニングを再開。同じパラメーターと戦略を使用し、短いキャプションの長さのデータセットを使用します。
-
精錬ステップ:手動で選ばれた高品質の画像を持つデータセットのサブセットを作成します。ステップ2の出力からのトレーニングを再開し、低学習(約7.5e-7)で、5から10のターンでコサインスケジューラーを用いて再設定します。結果が美的によいものになるまでトレーニングします。
固定トレーニングパラメーター
-
ノイズオフセットのような余分なノイズはなし。
-
Min SNR Gamma = 5: トレーニングを加速します。
-
完全なbf16精度。
-
AdamW8bitオプティマイザー:効率と性能のバランス。
データセット
-
解像度: 正規化されたSDXLのバケッティング戦略で、1024×1024の総解像度。
-
キャプション:WD14-Swinv2モデルで0.35の閾値でキャプション。
-
クローズアップクロップ:いくつかのクローズアップに画像をクロップします。トレーニング画像が大きいか稀である場合に非常に便利です。
-
トリガーワード:画像の最初のタグをトリガーワードとして保持します。
AIDXLv0.6
トレーニング戦略
AIDXLv0.52 からトレーニングを再開し、適応的な繰り返し戦略を採用します – データセットのそれぞれのキャプション付き画像に対して、以下のルールに基づいてそのトレーニングでの繰り返し数を増やします:
-
規則1:その画像の品質が高ければ高いほど、その繰り返し回数は多くなります;
-
規則2:その画像がスタイルクラスに属する場合:
-
そのクラスがまだ適合していないか未適合の場合、クラスの繰り返し回数を手動で増やすか、クラス内のデータの総繰り返し回数が約100に達するように自動的にその繰り返し回数を増やします。
-
そのクラスがすでに適合しているか過剰適合の場合、繰り返し回数を1に強制し、品質が低ければそのデータを削減します。
-
-
規則3:その最終的な繰り返し回数がある閾値を超えないようにします。これにより、コントロールが容易になります。
この戦略には次の利点があります:
-
新しいトレーニングからモデルのオリジナル情報を保護し、正則化された画像と同じ考えを持ちます;
-
トレーニングデータの影響をよりコントロールしやすくします;
-
適合していないクラスを奨励し、すでに適合しているクラスへの過剰適合を防ぎながら、異なるクラス間のトレーニングをバランスさせます;
-
計算リソースを大幅に節約し、モデルに新しいスタイルを追加するのが容易になります。
固定トレーニングパラメーター
AIDXLv0.51 と同じです。
データセット
AIDXLv0.6データセットはAIDXLv0.51を基にしています。また、次の最適化戦略が適用されています:
-
キャプションセマンティックソート:キャプションタグをセマンティック順にソートします。例:「銃、1男子、保持、短髪」->「1男子、短髪、保持、銃」。
-
キャプションの重複除去:重複したタグを削除し、その情報を保持するものを保持します。重複したタグは「長い髪」と「非常に長い髪」などの類似した意味を持つタグです。
-
追加タグ:すべての画像に手動で追加のタグを付与します。例:「高品質」、「インパスト」など。これを迅速に行うためのツールがいくつかあります。
VI AIDXL 対 AID
2023/08/08。AIDXL は AIDv2.10 と同じトレーニングセットでトレーニングされていますが、AIDv2.10 を上回っています。 AIDXLはよりスマートで、SD1.5ベースのモデルができない多くのことを達成し、概念を区別し、イメージディテールを学び、SD1.5やAIDが難しいまたは不可能な構図を処理します。それはまた、旧バージョンのAIDが完全にマスターできなかったスタイルを学びます。全体として、それは絶対的な可能性を持っています。AIDXLを更新し続けます。
VII スポンサーシップ
私たちの仕事が好きであれば、Ko-fi(https://ko-fi.com/eugeai) を通じて私たちをスポンサーして、私たちの研究開発をサポートしてください。ご支援誠にありがとうございます~
モデル紹介(中国語部分)
I 目录
この紹介では、以下のことを学びます:
-
模型介绍(见 II 部分);
-
使用指南(见 III 部分);
-
训练参数(见 IV 部分);
-
触发词列表(见附录 A 部分)
II 模型介绍
动漫插画设计XL,或称 AIDXL 是一款专用于生成二次元插图的模型。它内置了 800 种以上(随着更新越来越多)的插画风格,依靠特定触发词(见附录 A 部分)触发。
优点:构图大胆,没有摆拍感,主体突出,没有过多繁杂的细节,认识很多动漫人物(依靠角色日文名拼音触发,例如,“ayanami rei”对应角色“绫波丽”,“kamado nezuko”对应角色“祢豆子”)。
III 使用指南(将与时俱进)
1 基本用法
1.1 提示词书写
-
使用触发词:使用附录 A 所提供的触发词来风格化图像。适合的触发词将 极大地 提高生成质量;
-
提示词标签化:使用标签化的提示词描述生成对象;
-
提示词排序:排序您的提示词将有助于模型理解词义。推荐的标签顺序:
触发词(by xxx)->主角(1girl)->角色(frieren)->种族(elf)->构图(cowboy shot)->风格(impasto)->主题(fantasy)->主要环境(forest, day)->背景(gradient background)->动作(sitting)->表情(expressionless)->主要人物特征(white hair)->人体特征(twintails, green eyes, parted lip)->服饰(white dress)->服装配件(frills)->其他物品(magic wand)->次要环境(grass, sunshine)->美学(beautiful color, detailed, aesthetic)->质量(best quality)
-
负面提示词:worst quality, low quality, lowres, messy, abstract, ugly, disfigured, bad anatomy, deformed hands, fused fingers, signature, text, multi views
1.2 生成参数
-
分辨率:确保图像总分辨率(总分辨率=高度x宽度)围绕1024*1024且宽和高均为32的倍数。例如,832×1216 (3:2), 1216×832 (3:2), 以及 1024×1024 (1:1)。
-
不进行“Clip Skip”操作,即 Clip Skip = 1。
-
采样器和步数:采用 “euler_ancester” 采样器(sampler),该组合在 webui 里称为 Euler A。在 7 CFG Scale 上采样 28 步。
-
仅需要使用模型本身,而不使用精炼器(Refiner)。
-
使用基底模型 vae 或 sdxl-vae。
2 特殊用法
2.1 泛风格化
0.7 版本归纳了若干相似插画画风,引入了泛风格触发词。泛风格触发词各代表一种常见动漫插画画风类别。
请注意,泛风格触发词并不一定符合其词义指代的美术含义,而是经过重新定义的特殊触发词。
2.2 角色
0.7 版本对强化训练了角色。部分角色触发词的还原度已经能够达到 lora 的效果,且能够很好地将角色概念与其本身的着装分离。
角色触发方式为 角色名 \(作品\)。例如,触发动画《赛博朋克:边缘行者》的女主角露西则使用 lucy \(cyberpunk\);触发游戏《原神》中的角色甘雨则使用 ganyu \(genshin impact\)。这里,“lucy” 和 “ganyu” 为角色名,“\(cyberpunk\)” 和 “\(genshin impact\)” 则为对应角色的作品出处,括号使用斜杠”\”转义以防止被解释为提示词加权。对于部分角色,出处并非必要。
角色触发词请参照 selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co)。
在使用中,若仅靠单个角色触发词无法完全还原角色,则需要在提示词中添加该角色的主要特征。
角色触发词通常不会携带角色本身的着装特征,若要添加角色着装,则需要在提示词中添加衣物名。例如,游戏《碧蓝航线》中角色圣路易斯 ( st. louis \(luxurious wheels\) \(azur lane\) ) 的衣装触发可使用 silver evening gown, plunging neckline。类似地,您也能对任何角色添加其他角色的衣装标签。
2.3 质量标签
0.7 版本的质量和美学标签经过正式训练,在提示词中尾随它们将影响生成图像的质量。
0.7 版本正式训练并引入了质量标签,质量标签分为六个等级,由好到坏分别为:amazing quality, best quality, high quality, normal quality, low quality 和 worst quality.
2.4 美学标签
0.7 版本起引入了美学标签,描述图像的特殊美学特征。
2.5 风格融合
您可以将一些样式合并到您的自定义样式中。 “合并”实际上意味着一次使用多种风格触发词。 例如,chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
一些技巧:
-
控制风格的权重和顺序来调整最终风格。
-
尾随而非前置到提示词上。
3 注意事项
-
使用 SDXL 支持的 VAE 模型、文本嵌入(embeddings)模型和 Lora 模型。注意:sd-vae-ft-mse-original 不是支持 SDXL 的 vae;EasyNegative、badhandv4 等负面文本嵌入也不是支持 SDXL 的 embeddings;
-
对于 0.61 及以下版本:生成图像时,强烈推荐使用模型专用的负面文本嵌入(下载参见 Suggested Resources 栏),因其为模型特制,故对模型几乎仅有正面效果;
-
每个版本新增触发词将在当前版本效果相对较弱或不稳定。
IV 训练参数
以 SDXL1.0 为底模,使用大约 2w 张自己标注的图像在 5e-6 学习率,循环次数为 1 的余弦调度器上训练了约 100 期得到模型 A。之后在 2e-7 学习率,其余参数相同的条件下,训练得到模型 B。将模型 A 与 B 混合后得到 AIDXLv0.1 模型。
其他训练参数请参照英文版本的介绍。
VI 更新日志
2023/08/08:AIDXL 使用与 AIDv2.10 完全相同的训练集进行训练,但表现优于 AIDv2.10。AIDXL 更聪明,能做到很多以 SD1.5 为底模型无法做到的事。它还能很好地区分不同概念,学习图像细节,处理对 SD1.5 来说难于登天的构图,几近完美地学习旧版 AID 无法完全掌握的风格。总的来说,它拥有比 SD1.5 更高的上限,我会继续更新 AIDXL。
2024/01/27:0.7 版本新增了大量内容,数据集大小是上一版本的两倍以上。
-
为了得到令人满意的标注,我尝试了很多新的标签处理算法,例如标签排序、标签分层随机化、角色特征分离等等。项目地址:Eugeoter/sd-dataset-manager (github.com);
-
为了使训练可控,且更加服从我的意愿,我基于 Kohya-ss 制作了特制的训练脚本;
-
为了掌控不同世代的模型的融合过程,我开发了一些启发式的模型融合算法;为了使模型达到足够的风格化,我放弃了通过融合文本编码器和UNET的OUT层来提高模型的稳定和美学,因为这会伤害模型的风格。
-
为了筛选和过滤数据,我训练了一个水印检测模型、一个图像分类模型、一个美学评分模型,来帮助我清洗数据。
VII 赞助我们
如果您喜欢我们的工作,欢迎通过 Ko-fi(https://ko-fi.com/eugeai) 赞助我们,以支持我们的研究和开发,感谢您的支持!
Appendix / 附录
A. Special Trigger Words List / 特殊触发词列表
-
アートスタイルのトリガーワード: こちらをクリック
-
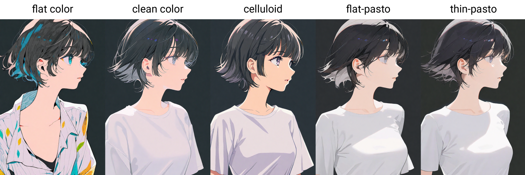
ペインティングスタイルのトリガーワード: フラットカラー、クリーンカラー、セルロイド、フラットパスト、薄パスト、擬似厚塗り、厚塗り、リアルな、写真リアルな、セルシェーディング、3D
-
フラットカラー: 平面の色彩、光と影をラインで描写
平涂:平面色彩,使用线条和色块描述光影和层次
-
クリーンカラー: フラットカラーとフラットパストの間のスタイル。シンプルできれいな着色。
具有简洁色彩的平涂,介于 flat color 和 flat-pasto 之间
-
セルロイド: アニメの着色
平涂赛璐璐:动漫着色
-
フラットパスト: ほとんどフラットカラーで、光と影をグラデーションで表現
接近平面的色彩,使用渐变描述光影和层次
-
薄パスト: 薄い輪郭線で、グラデーションと絵の具の厚さで光、影、レイヤーを描写
细轮廓勾线,使用渐变和颜料厚度描述光影和层次

-
擬似厚塗り:グラデーションと絵の具の厚さで光、影、レイヤーを描写
伪厚涂 / 半厚涂:使用渐变和颜料厚度描述光影和层次
-
厚塗り:ペンキの厚さで光、影、グラデーションを描写
厚涂:使用颜料厚度描述光影和层次
-
リアルな
写实
-
写真リアルな: リアルワールドに近いスタイルに再定義
相片写实主义:重定义为接近真实世界的风格
-
セルシェーディング: アニメ3Dモデリングスタイル
卡通渲染:二次元三维建模风格
-
3D
-
-
美的トリガーワード:
-
美しい
美丽
-
美的: やや抽象的な芸術感
唯美:稍微抽象的艺术感
-
詳細な
细致
-
美しい色: 微妙な色の使用
协调的色彩:精妙的用色
-
低解像度
-
ごちゃごちゃ: ごちゃごちゃした構図やディテール
杂乱:杂乱的构图或细节
-
-
品質トリガーワード:驚異的な品質、最高の品質、高い品質、低い品質、最悪の品質